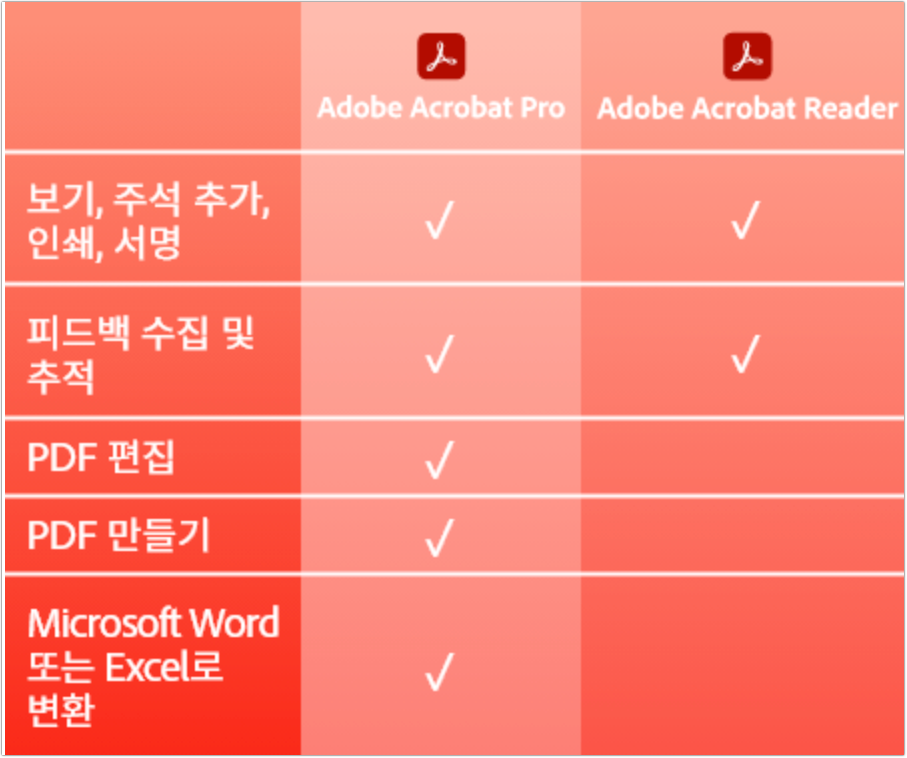
안녕하세요 룬슈입니다! 2022 생활스포츠지도사 필기 기출문제 PDF 파일로 가져왔습니다 :D 체육지도자연수원 사이트에서도 다운받으실 수 있지만 아이폰, 아이패드로 ...
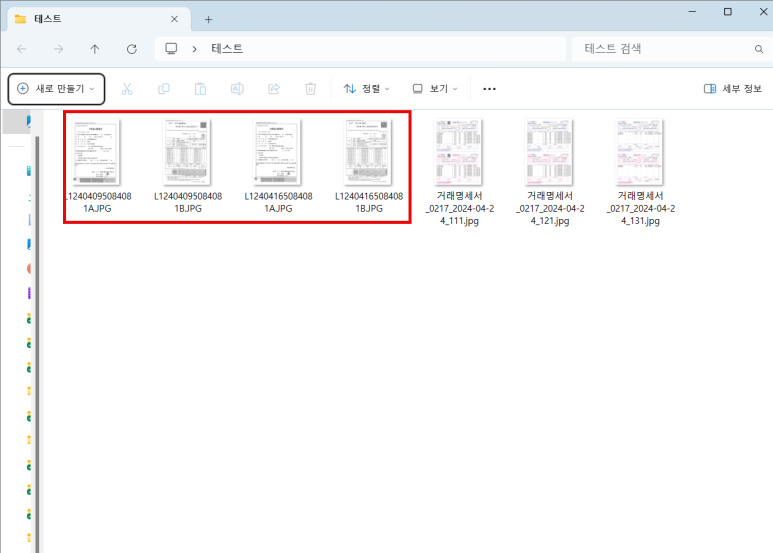
PDF에서 PowerPoint로 쉽게 변환하는 5가지 방법 PDF 파일을 PowerPoint 프레젠테이션으로 변환하는 것은 작업 효율을 높이고 다양한 목적으로 프레젠테이션을 활용하...
안녕하세요, 에듀로(edu-law) 변성숙입니다. 다음주 여수에서 교육장들 대상으로 교육부의 교권보호 정책과 교권보호 5법을 발표하는데요. 함께 읽어보는 것도 좋을 듯 하여 교육...