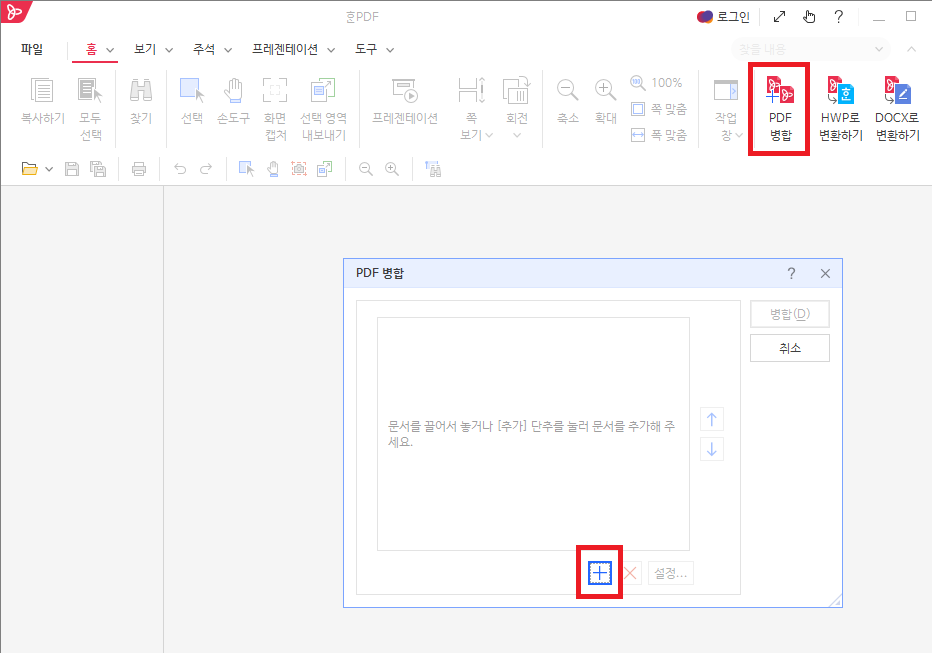
오늘은 PDF 파일 용량 줄이기에 대해 알아볼 거야. PDF 파일은 보고서, 이력서, 프리젠테이션 등 다양하게 사용되는데, 때로는 이 파일들이 너무 커서 이메일로 보내기 어렵거나 ...
pdf 뷰어 무료 Adobe Acrobat Reader DC 설치 방법을 알아보자. 우리가 일상에서 흔히 사용하는 어도비 아크로뱃 PDF 뷰어의 설치 방법 및 실행 하는법에 대해...
안녕하세요. 랜선닷컴입니다. 너~무 오랫만에 인사드립니다. 여러분 무탈하게 잘 지내셨지요? 갑자기 고3 수험생인 저희 아이가 전방십자인대파열과 반월판 연골 파열로 인해 급하게 수...