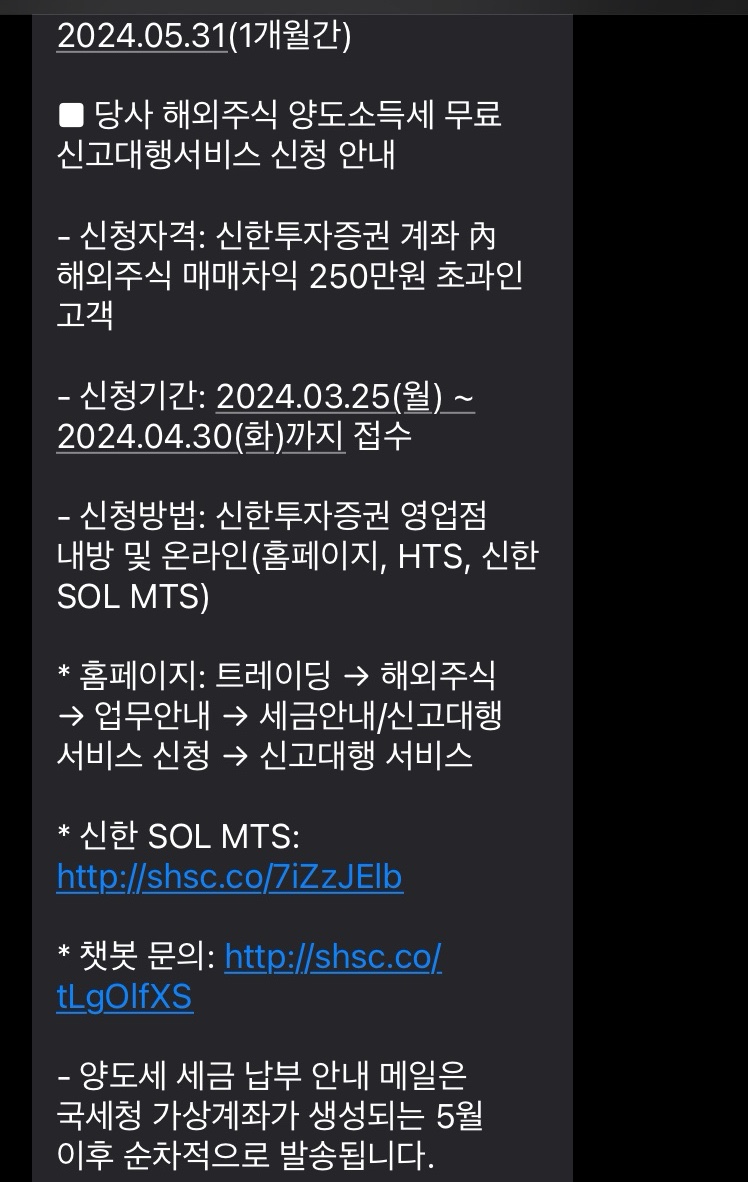
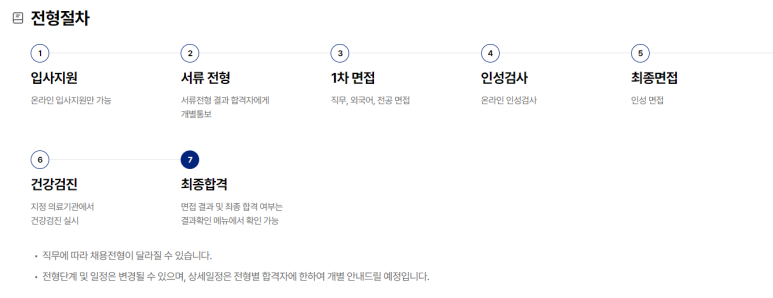
신한 금융투자에서 2,500,000원 이상 양도 차액이 있는 사람들에게 양도소득세 신고를 대행 해준다는 문자가 왔다. 해외 주식을 하는데 양도 차액이 2,500,000원 이상인 ...
안녕하세요! 은인세무회계입니다. 다가오는 5월은 종합소득세 신고 및 납부의 달 입니다. 종합소득세 신고 전, 홈택스에서 신고 유형 등을 확인할 수 있는 안내문이 발급되는데, ...
아이패드 굿노트 PDF파일 검색기능 사용하기(OCR) 알려드릴게요. 짧고 간단하게 썼습니다! 🚩아이패드 굿노트에서 PDF파일에 검색기능을 사용하기 위해서는 [Adobe Scan]앱...