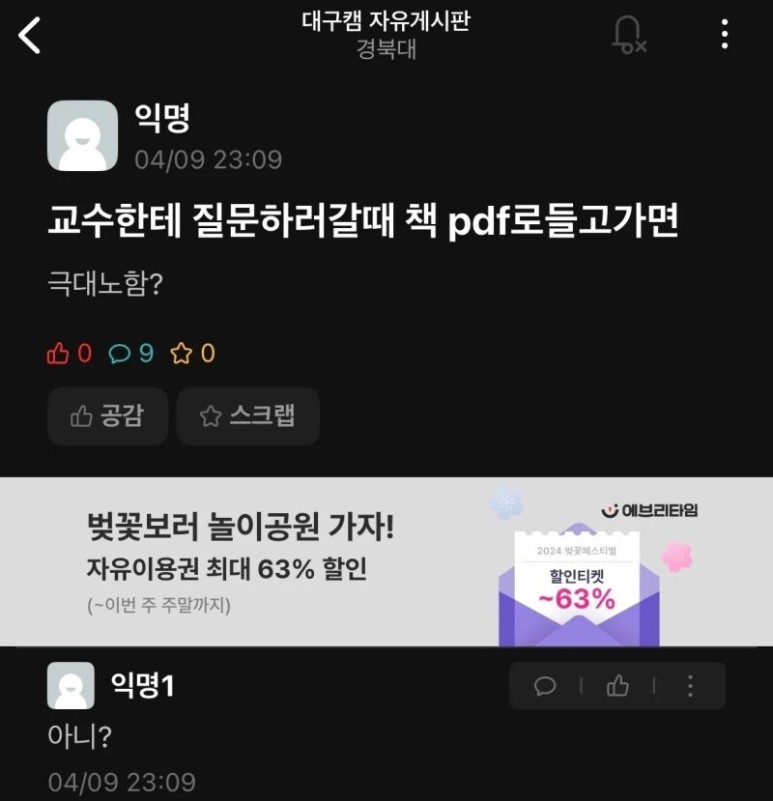
안녕하세요 꿍마입니다 엊그제 월요일에 티슬로 디스커버리 키트들을 주문했어요 지금 티슬로 사이트에 가보시면 4월 한달 바디크림 디스커버리 키트가 1인 한정 1회 무료로 받아 볼 수 ...
LG U TV 유플러스 채널 번호 안내 IPTV 분야별 편성표 2023년 8월 현재 다운로드 pdf LG U+ TV 유플러스 채널 번호 안내 IPTV 분야별 편성표 2023년 8...
종합소득세 신고서 확인 및 발급 (홈택스) 종합소득세 신고서 확인 및 발급! 홈택스 이용 출력 및 PDF 파일 1. 접속하기 1 / 2 자주찾는 메뉴 1 / 2 근로장려금...